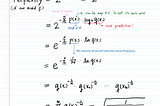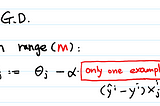InIntuitionMathbyAerin KimWhat is column space? (with a Machine Learning example)When people say vector space, column space, subspace, etc., what do they mean by “SPACE”?Apr 8, 20196Apr 8, 20196
InIntuitionMathbyAerin KimWhat is a Positive Definite Matrix?and why does it matter?Jan 4, 201910Jan 4, 201910
InTDS ArchivebyAerin KimMoment Generating Function ExplainedIts examples and propertiesSep 24, 201918Sep 24, 201918
InTDS ArchivebyAerin KimGamma Function — Intuition, Derivation, and ExamplesIts properties, proofs & graphsNov 23, 20193Nov 23, 20193
InTDS ArchivebyAerin KimConditional Independence — The Backbone of Bayesian NetworksConditional Independence Intuition, Derivation, and ExamplesOct 5, 201911Oct 5, 201911
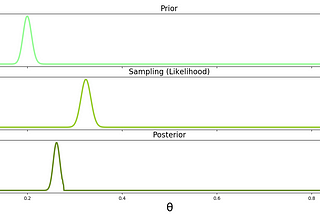
InTDS ArchivebyAerin KimBayesian Inference — Intuition and Examplewith Python CodeJan 2, 202023Jan 2, 202023
InTDS ArchivebyAerin KimPDF is not a probability.The probability density at x can be greater than one but then, how can it integrate to one?Aug 26, 201917Aug 26, 201917
InTDS ArchivebyAerin KimPoisson Distribution Intuition (and derivation)When to use a Poisson Distribution?Jun 1, 201940Jun 1, 201940
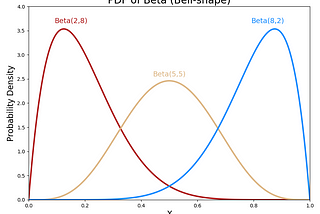
InTDS ArchivebyAerin KimBeta Distribution — Intuition, Examples, and DerivationWhen to use Beta distributionJan 8, 202025Jan 8, 202025
InTDS ArchivebyAerin KimGamma Distribution — Intuition, Derivation, and Examplesand why does it matter?Oct 12, 201917Oct 12, 201917
InIntuitionMathbyAerin KimLet’s derive Chi-Squared PDF from normal distribution *intuitively*We can calculate the probability density function (PDF) of a random variable from its cumulative distribution function (CDF) using…Sep 10, 20171Sep 10, 20171
InIntuitionMathbyAerin KimWhy the Normal (Gaussian) PDF looks the way it doesAlthough this might not be the most rigorous derivation of the Gaussian PDF (Probability Density Function), this note might help you…Aug 24, 20173Aug 24, 20173
InTDS ArchivebyAerin KimThe intuition behind Shannon’s Entropy[WARNING: TOO EASY!]Sep 29, 201813Sep 29, 201813
InTDS ArchivebyAerin KimPerplexity Intuition (and Derivation)Never be perplexed again by perplexity.Oct 11, 201811Oct 11, 201811
InIntuitionMathbyAerin KimThe difference between Batch Gradient Descent and Stochastic Gradient Descent[WARNING: TOO EASY!]Sep 21, 201731Sep 21, 201731
InIntuitionMathbyAerin KimHow to implement the derivative of Softmax independently from any loss functionThe main job of the Softmax function is to turn a vector of real numbers into probabilities.Sep 3, 201711Sep 3, 201711
InIntuitionMathbyAerin KimWhy is the inner product of orthogonal vectors zero?It is “by definition”. Two non-zero vectors are said to be orthogonal when (if and only if) their dot product is zero.Mar 31, 20193Mar 31, 20193
InIntuitionMathbyAerin KimWhy is the second Principal Component orthogonal (perpendicular) to the first one?Because the second Principal Component should capture the highest variance from what is left after the first Principal Component explains…Aug 23, 20172Aug 23, 20172
InIntuitionMathbyAerin KimNormal Equation for Linear RegressionFrequently Asked FAMGA Applied Scientist Interview QuestionOct 6, 20176Oct 6, 20176